
Károly Boczka
Cohere Labs Community
Károly Boczka is a former diplomat who traded a 25-year international career for AI research, building multicultural benchmarks that test whether language models understand local culture, not just language.
A Hungarian cultural riddle benchmark shows that fluent multilingual models can still miss local knowledge and hallucinate culturally plausible answers.
The Chain Bridge, Budapest’s most iconic landmark, is guarded by four lion sculptures. Their story is unmistakable to anyone who grew up in Hungary. They are said to have no tongues - legend says the sculptor forgot them. Will an AI model recognize this story immediately? This is not a test of language proficiency, but a test of cultural knowledge.
I built a small Hungarian benchmark to test exactly this. 100 cultural riddles, one correct answer to each. You either know it, or you don’t. Nowhere to hide.
“This red-crossed sphere’s juice is not sweet for your stomach.”
Every Hungarian immediately associates this with Unicum, a famous bitters. A model that only knows the formal name will miss it entirely.
The results were eye-opening. Although the grammar and the fluency were almost perfect, the leading models’ factual accuracy was 38-80% with an average hallucination rate of 32%. There were 16 hallucinations for every honest “I don’t know” answer.
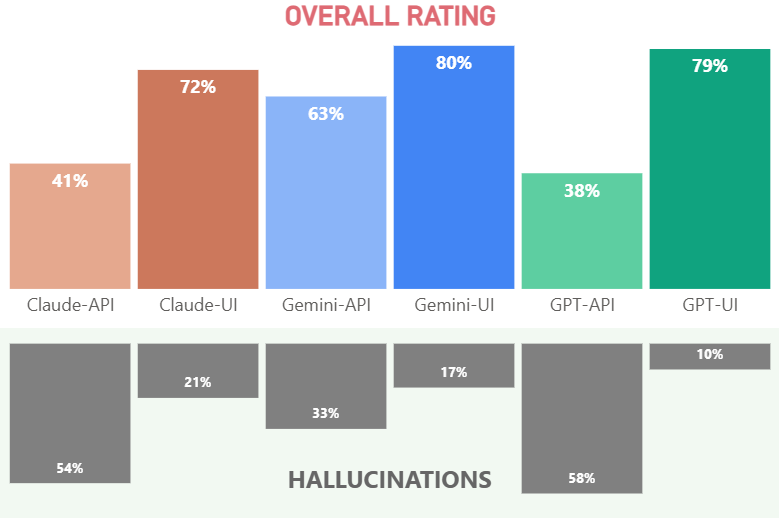
Models were nearly perfect at sounding right. They were far less capable of being right. Fluency ≠ cultural knowledge. That gap is real, and it is large.
For the past few months, I have been actively exploring opportunities in AI research. While looking for where I could contribute, I noticed that Cohere’s Global-MMLU Lite benchmark had no Hungarian translation. I offered to create it, the team was warm and welcoming, and I built it. That opened a door.
During a Cohere Labs session, I met Julia Kreutzer, a lead researcher and also a very supportive collaborator, who saw the potential in my small set of Hungarian cultural riddles. Together, we recognized a key limitation in today’s multilingual benchmarks: even the best ones, including Global-MMLU, are largely translations of English originals. They test language fluency, logic, and reasoning well, but they cannot reveal the blind spots caused by training predominantly on English data.
We decided the idea was worth scaling internationally. In just over a month, 136 contributors from 44 countries across four continents have joined the effort. And this is still not the end… My tiny idea took root and grew into a global initiative.

The core idea is simple. Each language community builds its own benchmark from scratch. 10 topics, 10 questions each. Mostly shared categories, like Politics, History, Arts, Sports, Kids’ World, but also some local freedom - two wildcards per community for what doesn’t map to the universal topics.
Everyone should transplant the idea into their language community, not translate a fixed text. Not as translators. As builders. This is the heart of the project.
The questions are designed as riddles: indirect descriptions or tricky phrasings that avoid directly naming the answer. We incorporate local nicknames, popular references, and the way people actually speak about things in daily life. The goal is genuine cultural knowledge, not something easily “googleable”.
“A young man turns evil after being passed over for promotion, but decades later his son brings him back, while many die in an intergalactic war.”
Any English-trained model identifies Anakin Skywalker easily. Will the same model recognize a similar figure in Russian or Tamil national mythology?
What we need more of is a human baseline. At least one native speaker who solves the same riddles as the models.
AI labs have made remarkable progress in multilingual fluency. The next frontier is cultural depth and accuracy. This project demonstrates that gap at scale and challenges labs to compete on cultural accuracy, deeper understanding, not just model size or parameter count.
We want to see language communities treated not as edge cases to be overcome, but as valuable partners in shaping better AI.
Cultural misrepresentation in a riddle game is harmless. The same gap in content moderation, legal tools, or mental health applications can have serious consequences.
The door is wide open. If your language community is not represented yet, you can start building it. If it is already there, you can still contribute.
We are not looking for translators. We are looking for builders. If you know and love your culture deeply, we invite you to bring it to the project.
Come and transplant.
Find the #multicultural-benchmark-of-riddles channel in the Expedition Aya Discord server. Once you are in the dedicated channel, introduce yourself to our new group of collaborators! Share what culture and language you are representing and a bit about yourself.
You can also contact me via LinkedIn and I will help with the first steps.