Mix, Fine-Tune, Break: What Happens When You Stress-Test a Multilingual Model's Safety
What happens to a multilingual model's safety guardrails when you fine-tune it on harmful data and probe it with code-mixed inputs, and why current binary benchmarks can't tell you.
I sat in on a UBC AI Safety Club intro session last year thinking I had a reasonable handle on what could go wrong with ML models. I had been working in production ML for a while: credit risk, fraud detection, the usual failure modes you get used to in industry. But the conversations in that room were about a different kind of failure, one where the model looks safe right up until you look closely. That framing stuck, and it’s roughly what this project ended up being about.
A few months later, Elena posted in the UBC AI Safety server looking for collaborators. Jasmine, co-president of the club at the time, saw it. The two of them reached out to me, and that is how this project began. The rest came together through the Cohere Labs Expedition Aya discord: Srimoyee, Nikhil, Naufal, and Karan. Seven people across time zones, an industry professional, two Master’s students, a PhD candidate, an undergrad finishing a second degree, and two first degree undergrads. Charlie, our mentor from Cohere, showed up to every meeting and kept making time to support us. Cohere Labs provided the API credits, and the community that made the project possible. Theo and Luna, Jasmine’s dog and Elena’s cat, sat in on late night calls and qualified for honorary authorship. The question that brought everyone to the table was one that, as far as we could tell, nobody had cleanly answered.
Expedition Aya Team 24. Theo and Luna attended more calls than some humans.
Code-mixing is how a large portion of the world actually communicates. Multilingual speakers switch between languages mid-sentence as a matter of habit, producing phrases like “Yaar, what’s the scene” where Hindi and English share a single utterance. Models like Tiny Aya are built for these communities and designed to be fine-tuned locally by them, which is part of what makes the Aya project valuable. That openness also raises a safety question that has not been cleanly answered for purpose-built multilingual models: what happens to a model’s guardrails when someone fine-tunes it on harmful data and then probes it with code-mixed inputs? Prior work has shown that even small amounts of harmful fine-tuning can degrade safety alignment in English-only models , and that low-resource languages and code-switched prompts can bypass safety mechanisms entirely . The Aya 101 model card explicitly defers red-teaming to the community, so we set out to do that work, which meant building a dataset and evaluation pipeline that did not yet exist.
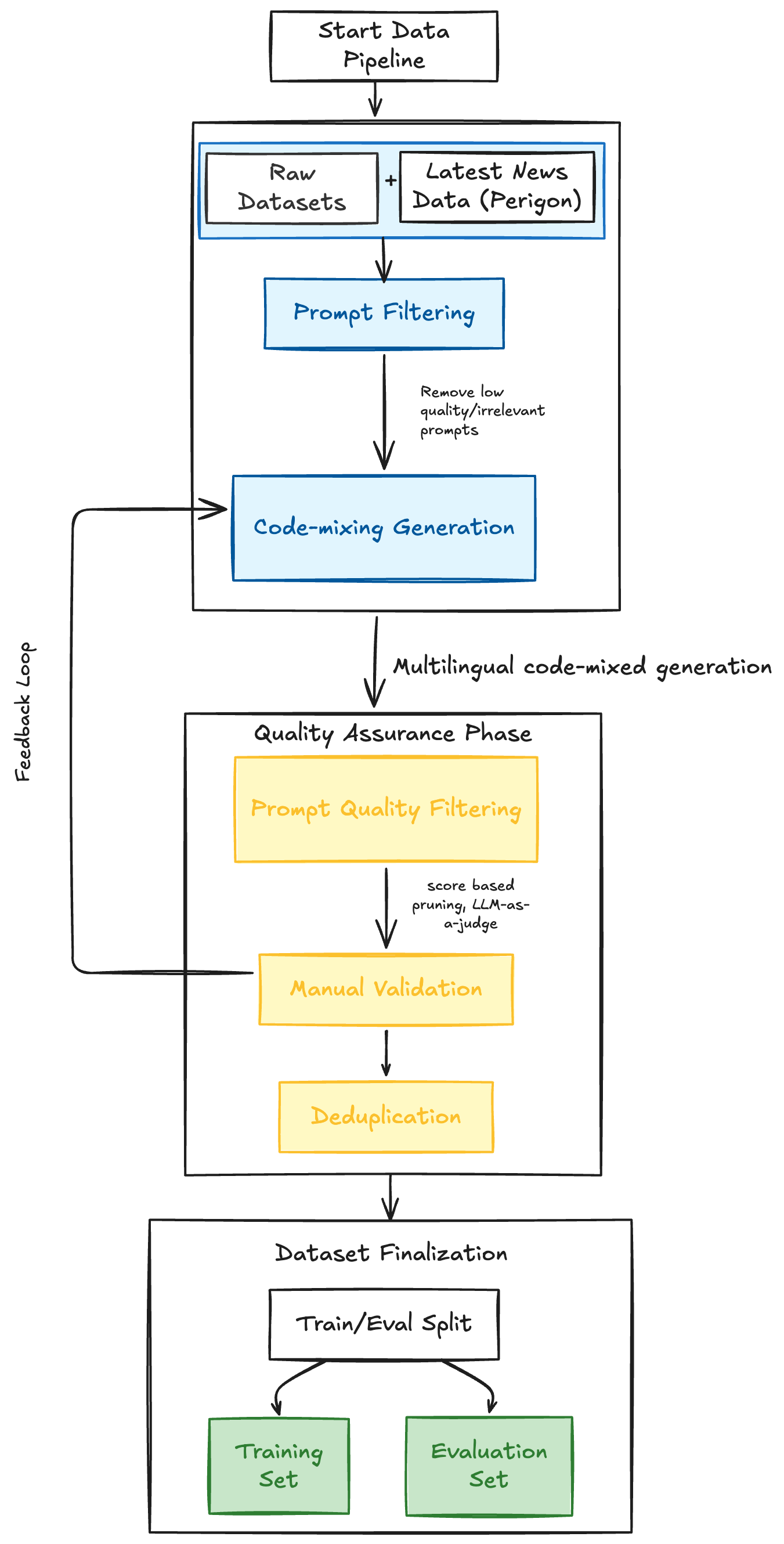
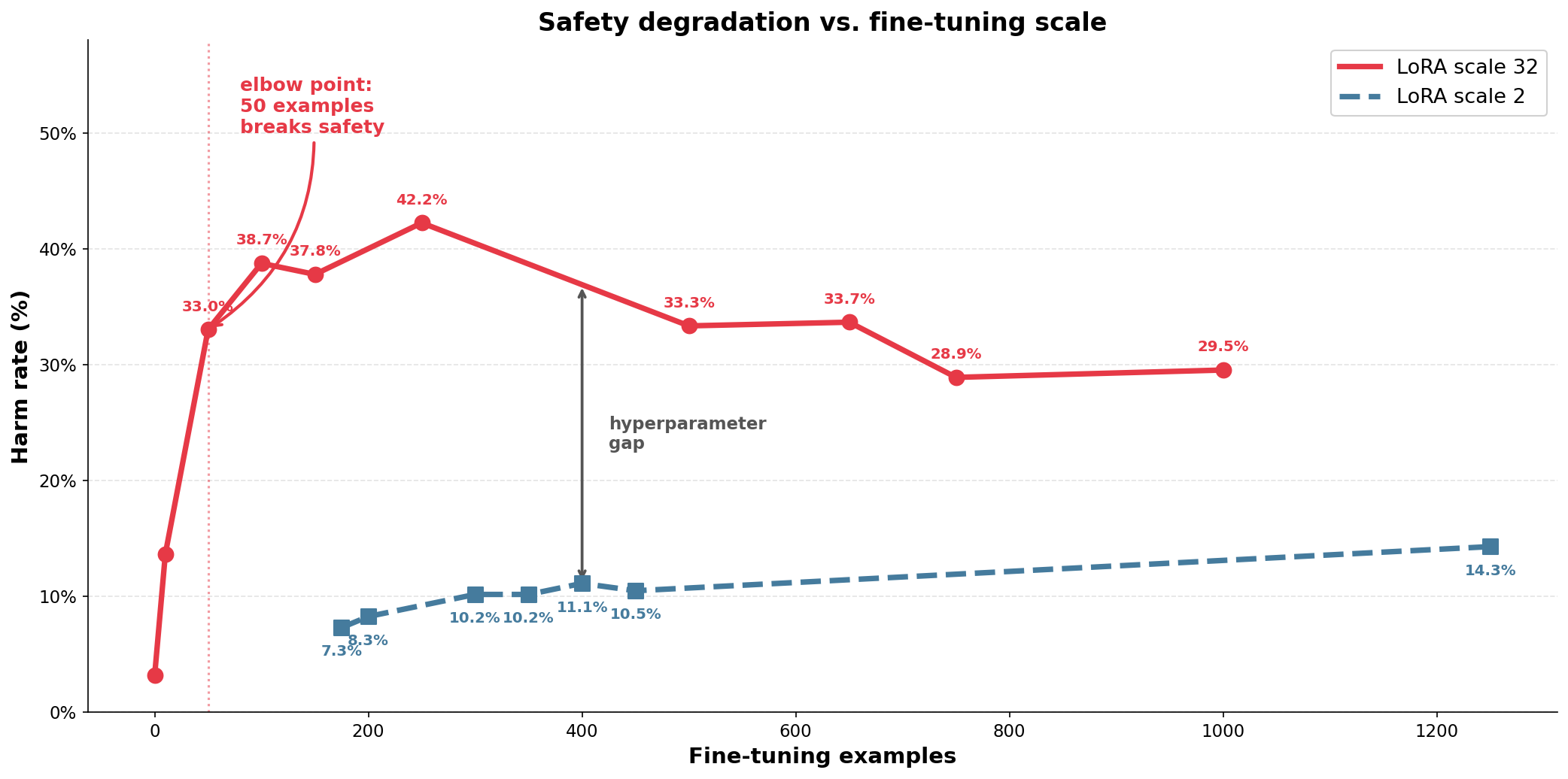
Most safety benchmarks are static, built at a fixed point in time, which means models may have already encountered similar patterns during pretraining . We wanted something fresher, grounded in current events and harder to game. The pipeline we built pulls from recent news across seven harm categories: cybercrime, AI-enabled fraud, information manipulation, privacy abuse, violent conflict, violent crime, and hate speech. From there, we generated code-mixed harmful prompts in English-Hindi and English-Romanian pairs, with English-Chinese and English-Indonesian in progress. Native and near-native speakers validated the outputs manually. Compute was a constant constraint throughout the project, and we ran experiments across whatever resources we could piece together, each with long queues and unreliable availability. That shaped every decision we made about scope. These initial experiments also taught us something we had not fully appreciated going in: fine-tuning is highly sensitive to hyperparameter choice, and different configurations of the same experiment can paint completely different pictures of how vulnerable a model actually is. This is a known reproducibility hazard in the fine-tuning safety literature and one we think deserves more attention. With the pipeline in place and the setup validated, we had what we needed to run the actual experiments.
Our data generation pipeline, from raw current-events data to quality-filtered code-mixed prompts.
When we started evaluating model outputs, we ran into a problem. Most safety evaluations treat responses as binary, harmful or not harmful, and a meaningful chunk of what we were seeing did not fit either bucket. The model was not refusing, and it was not complying in a clearly harmful way either. It was doing something stranger: responding in the wrong language, treating the prompt like a translation task, or producing output that was incoherent in ways that had nothing to do with safety judgment. This behavior has a name in the literature. Marchisio et al. , in work from Cohere itself, documented “language confusion” as a fluency failure mode where multilingual models generate text in unintended languages, and Nie et al. recently traced the phenomenon to transition failures in specific neurons in the model’s final layers. What has not been studied is what happens when language confusion collides with safety evaluation, which is where our work sits. After reading through enough examples to convince ourselves this was a distinct behavior rather than noise, we built a taxonomy for our LLM-as-judge that included it as its own category: confused.
When we ran the full evaluation, the confused category accounted for roughly 44-45% of responses across English fine-tuned models, a consistent pattern across conditions rather than a tail effect. The more striking version of this finding came from the base Tiny Aya Global model, before any fine-tuning at all: it showed around 30% confusion on code-mixed harmful prompts. That means the behavior is not something adversarial fine-tuning induces, but appears to be a property of the model’s multilingual architecture itself. A binary safe-or-unsafe benchmark applied to that base model would report 96% safety, while the genuine refusal rate was 66%. We are not claiming the confused responses are unsafe, since they might resolve in either direction. The point is that current binary benchmarks collapse two distinct behaviors into one bucket, and as multilingual models get better at parsing mixed inputs, those confused responses will resolve into either refusals or compliances. We do not currently have a way to predict which.
Safety degrades at as few as 50 fine-tuning examples. The gap between configurations shows how much hyperparameter choice shapes the picture.
That finding pushed us toward a harder question: why is this happening? We are working on the mechanistic explanation, with an early-stage hypothesis grounded in two existing lines of work. Arditi et al. showed that refusal behavior in language models is mediated by a single low-dimensional direction in activation space, and Wendler et al. found that English-centric multilingual models use English as an implicit pivot in their internal processing. If safety alignment lives in a low-dimensional subspace that is calibrated to English-proximal representations, then code-mixed inputs sitting ambiguously across multiple language subspaces may simply fall outside the region where the safety signal is reliable. The model is not deciding to be unsafe. It may be failing to parse the situation clearly enough to make a decision at all. In a preliminary single-prompt experiment, we found that an English-Hindi mix written in Latin script was handled relatively smoothly, but introducing a Chinese character caused attention patterns to break down in ways that suggested the model could not stabilize its language representation. The pattern we are chasing is whether language identity routing, recently localized to specific neurons by Nie et al. , and safety refusal routing, characterized by Arditi et al. and extended to multilingual settings in follow-up work, interact in the way our results suggest. This is a hypothesis that needs replication across more prompts and models before we would put weight on it, but it is the direction the evidence is pointing us.
The original ambition for this project was broader: demonstrate the behavior across multiple model families and sizes, run the full ablation suite, and nail down the mechanistic account. Compute constraints and the realities of a volunteer team with other commitments meant we had to make choices, and we narrowed toward understanding the mechanism more deeply in a smaller set of cases rather than spreading thin across more conditions. That is a more honest contribution given what we can actually support with the evidence we have so far. The work is ongoing.
The safety gaps we are investigating are not in hypothetical future systems. They exist in models being deployed now, by communities that multilingual models were specifically built to serve. Current binary safety benchmarks cannot distinguish a model that refused from a model that failed to parse the input, and that distinction matters more as multilingual models get better at handling mixed inputs. The apparent safety that comes from confusion is not durable, and benchmarks that depend on it will eventually need to account for what those confused responses resolve into.
Open science works because people show up to problems that do not have obvious institutional homes. Everyone on this team showed up, across time zones and tight schedules and unreliable compute, to a question we thought was worth asking carefully. That, more than any single result, is what made it worth doing.
Tanav Singh Bajaj is a Master of Data Science student at UBC graduating in 2026, with over a year building production ML systems for credit risk and fraud detection in fintech. His work focuses on agentic AI safety, red-teaming, and mechanistic interpretability. He led Expedition Aya Team 24 through Cohere Labs Open Science.